ClickHouse是由俄罗斯的Yandex开发, 并于2016年开源发布的一种分布式列式数据库管理系统(DBMS). 其专为处理大规模数据分析和数据仓库工作负载而设计, 别适用于处理大规模数据集和复杂查询, 被广泛应用于数据分析, 日志分析, 实时报表和数据仓库等场景.
ClickHouse采用了列式存储结构, 多级压缩和向量化查询等技术, 具有较高的查询性能和扩展性. 此外ClickHouse还完全支持标准的SQL查询语言, 使得开发人员可以使用熟悉的SQL语法进行数据分析和查询.
当前基于云服务的Clickhouse产品价格较高, 按月付费大约需要1000+元, 按量付费每小时也需要8+元. 因此建议在本地安装和部署Clickhouse来体验相关功能.
列式存储
列式存储是ClickHouse的核心特性之一, 它与传统的关系型数据库常用的行式存储形成鲜明对比. 其主要思想是将数据按照列而不是按照行来组织和存储, 从而将同一列的数据都连续存放在一起.
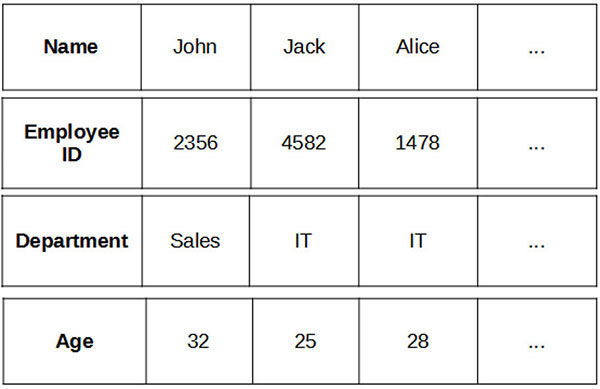
通过这种存储方式的改变, 查询可以只读取必要的列, 从而降低了数据遍历成本, 执行数据聚合操作(SUM等函数)时效率也更高. 同时同一列内的数据相似度高, 因此更容易被压缩.
MergeTree引擎
MergeTree引擎是Clickhouse底层的多种实现引擎中的一种, 也是最常见的实现引擎. MergeTree引擎规定了数据的存储方式和支持的查询模式, 因此理解MergeTree引擎的实现原理有助于理解为什么Clickhouse提供了如此的特性.
给定一组数据, 其按照传统的行式存储时结构如下:
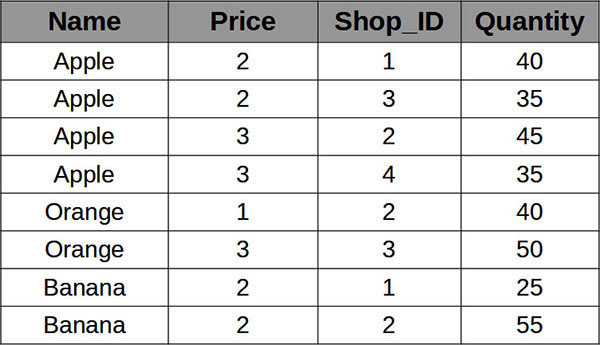
则在MergeTree引擎下的存储结构如下所示
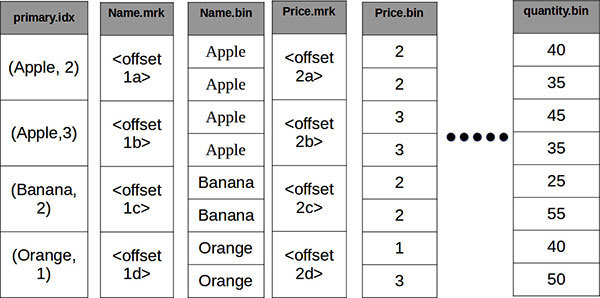
列式存储: 每一列都有一个单独的.bin文件(Name.bin和Price.bin等), 其中的数据按照列存储,
数据顺序: 每一列的数据都按照主键的顺序排列. 此处将(Name, Price)定义为主键, 因此其组合是顺序的.
稀疏索引: 每个数据片段在逻辑上被分成多个颗粒(granules), 此处将index_granularity定义为2, 因此每2行数据构造一个granules. Clickhouse的索引只会标记每个granules的第一行数据, 因此索引文件中不包含被索引字段的全部数据. 这类索引因此被称为稀疏索引. 稀疏索引能够以较小的索引体积记录大量的数据, 因此可以常驻内存.
列索引: 对于每一列, 还有一个单独的.mrk文件, 其中标记了每个granules在文件中的偏移位置, 因此在查询时可根据该数据直接定位到数据的位置, 减少扫描的时间.
插入与合并: 新数据会根据主键的顺序插入到相应的分区中, 如果插入的数据与已有的分区重叠, 则会触发合并操作, 将重叠的分区合并成一个更大的分区, 同时进行数据合并和压缩.
数据分区:MergeTree将数据按照时间或其他指定的分区键进行分区, 每个分区存储在一个单独的目录中, 减少查询时需要扫描的数据量.
跳数索引: 跳数索引是指数据片段按照granules分割成小块后, 将多个granules组合成一个大的块, 对这些大块写入索引信息. 这样有助于使用where筛选时跳过大量不必要的数据, 减少SELECT需要读取的数据量.
因此与跳跃表并无任何关系, 这个名字实在是容易产生误导
MergeTree支持3类跳数索引, 分别是minmax(记录一段区间的最大值和最小值, 便于快速判断指定数据是否位于该区间内), set(使用哈希表记录所有数据)和布隆过滤器(快速判断是否包含指定数据)
参考资料
以下三篇文章中, 第一篇文章对MergeTree的原理有较为全面的介绍. 第二篇文章对跳数索引有更多详细的解释. 第三篇文章是官方文档, 对MergeTree相关内容的介绍最为准确和详细.
- 万字长文深度解析Clickhouse MergeTree底层原理
- ClickHouse 中最重要的表引擎:MergeTree 的深度原理解析 - 古明地盆 - 博客园
- MergeTree | ClickHouse Docs
数据压缩
数据压缩是提高存储效率和I/O性能的关键技术。ClickHouse内置了多种压缩算法,并允许用户根据具体需求进行选择和配置。
主要特点
多种压缩算法:支持LZ4、ZSTD、Deflate等压缩算法,每种算法在压缩比和压缩/解压速度之间有不同的权衡。
自动压缩:ClickHouse可以在数据写入磁盘时自动进行压缩,并在读取时解压。
分区和分片级别的压缩:可以在不同的数据分区或分片上应用不同的压缩策略。
压缩的好处
节省存储空间:通过去除冗余数据和利用数据的局部性,显著减少所需的物理存储空间。
加速数据传输:压缩后的数据占用更少的带宽,特别是在网络传输过程中。
向量化技术
向量化是ClickHouse用来进一步提高查询性能的一种重要技术。
核心思想
批量处理:向量化技术允许数据库引擎一次处理多个数据值(即一个向量),而不是逐个处理单个值。
SIMD指令集利用:现代CPU支持SIMD(单指令多数据)指令集,向量化能够充分利用这些指令集进行并行计算。
实施细节
查询优化器:ClickHouse的查询优化器会尝试将可以向量化的操作转换为对应的向量操作。
内置函数支持:许多内置函数都已经过优化,以支持向量化执行。
性能优势
显著提高计算速度:通过并行处理,向量化可以大大加快数据处理速度,尤其是在大规模数据集上执行复杂计算时。
减少CPU周期消耗:相比于逐条处理记录,向量化减少了循环开销和条件判断次数。
使用实践
导入数据
1 | Query id: 041b433b-c386-459c-99a1-f335da5c7f75 |
查询数据
1 | 30 rows in set. Elapsed: 0.062 sec. Processed 29.30 million rows, 175.80 MB (473.14 million rows/s., 2.84 GB/s.) |
查询数据本质上取决于磁盘性能, 但总体上来说, 确实可以实现声称的亿级别的行处理速度
参考资料
最后更新: 2026年07月25日 12:35
版权声明:本文为原创文章,转载请注明出处
原始链接: https://lizec.top/2024/08/18/ClickHouse%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0/