本文介绍Go语言最常用的模块, 包括基础的数据结构(数组, 切片, 哈希表), 基本的IO操作, 字符串操作, 并发控制和反射相关的内容. 由于Go并不是我的第一门语言, 所以本文将对照C, Java, Python等语言已有的语法进行对比. 对于其他语言中已有的内容, 会比较简略地带过.
数组
数组是基础的数据结构, 不同于C语言中所有数组类型的变量本质上都是指针的实现, Go语言中的数组变量具有值类型的语义, 在Go语言中数组既包含类型又包含长度, 类型和长度完全相同的数组才是为同一个类型.
数组可以直接初始化, 也可以不指定长度, 由编译器推导数组的长度, 例如
1 | arr1 := [3]int{1, 2, 3} |
注意: 不可使用
[]int{1,2,3}的形式初始化, 因为这是切片的语法
数组初始化时可以直接指定某个位置的值, 使用此方式时, 没有被指定的位置默认使用零值, 例如
1 | a := [...]string{0:"A", 25:"Z"} |
GO语言中数组是值类型, 采用拷贝传递, 因此向函数传递数组会导致数组被复制. 因此一般不会将数组作为参数, 而是将可变的切片作为参数. 如果数组中的元素可以比较, 那么可以直接使用==比较两个数组是否相同. 此时当且仅当数组中每个元素都对应相等时, 两个数组才相等
由于数组的上述特性, 一般很少直接使用数组, 只有类似于IP地址这种明确元素数量的场景中会使用数组作为参数.
切片(变长数组)
Go语言的Slice是一个没有正交的数据结构, 在实际使用过程中具有对数组的引用和可变长数组两种功能. 在使用过程中应该尽量避免同时使用Slice的两种功能. 以下分别介绍作为切片的Slice和作为变长数组的Slice.
作为切片的Slice
Go的数组是值语义, 而C系列的语言对于数组都是视为引用语义, 因此直接将数组作为函数参数传递时会遇到很多问题, 例如值传递导致较高的拷贝开销, 无法在函数内修改数组等. 为了解决这一问题, Go引入了切片数据结构. 切片可以视为对数组的一个片段的引用. 切片是一个轻量级的数据结构, 其中只包含了引用数据的指针和切片的长度, 以及切片剩余的容量, 切片结构示意图如下所示
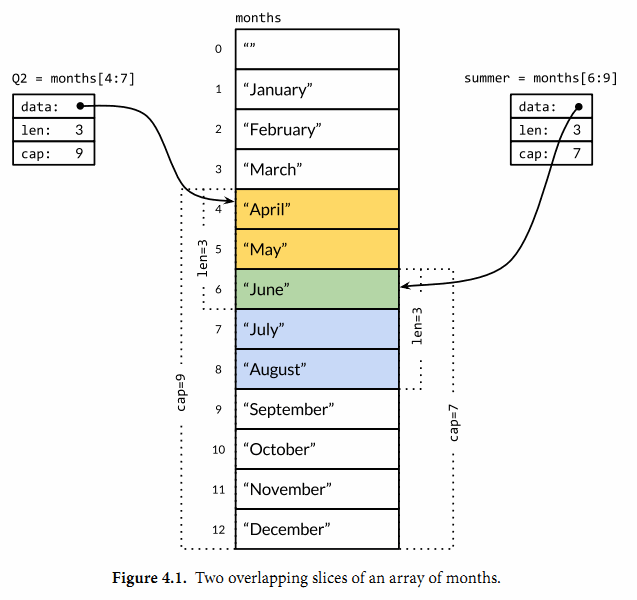
由于每个变量在编译时就可以确定类型, 因此切片中不需要存储类型信息.
切片是一个数据片段的引用, 因此主要通过如下的方式产生切片:
1 | var s1 []int // 直接声明一个切片, 不指向任何数组 |
切片的截取操作与Python中的切片语法基本一致, 但在Go语言中
- 切片索引越界会直接导致程序错误.
- 不支持负数索引
- 由于切片是对数据的引用, 因此修改切片会导致底层数据被修改.
Go语言推崇 显式优于隐式 的设计哲学, 所以负数这种语法糖是别想吃了
除了常规的切片语法外, GO还支持三索引切片的语法, 例如
1 | // 创建一个数组 |
通过指定切片的容量, 可以在后续操作该切片导致容量超出预期时产生错误, 从而提前发现相关的问题
作为变长数组的Slice
Slice也可以当做一个可变长的数组使用, 可以使用如下的方式定义变长数组
1 | var s1 []int // 直接声明一个切片, 不指向任何数组 |
其中的make函数的原型为make([]T, length, capacity), 长度和容量指的是当前的实际长度和可以存放数据的最大长度.
使用
len()和cap()函数获取切片的长度和容量
1 | // 创建变长数组, Len是实际空间, 容量是数组的剩余空间 |
注意: 如果指定了长度, 则其中的元素会初始化为相应的零值. 但如果仅指定了容量, 则没有进行任何操作.
向切片中添加数据时, 根据底层的数据结构是否还有空间, 新添加的数据可能原地添加, 也可能复制到一个新的内存之中. 因此append方法要有返回值而不能原地调用.
切片转换语法
使用a[:]将数组a转换为一个切片, 使用s...将切片s展开为多个参数
排序
由于切片排序是一个常用操作, 因此从Go 1.8开始, sort包提供如下的排序函数
1 | func Slice(x any, less func(i, j int) bool) |
其中less函数给定了数组中的两个元素, 需要返回两种的大小关系, 例如
1 | arr := [10]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9} |
对于复杂的数据结构, 可以通过实现sort包中定义的三个接口实现排序, 可参考下面的文章
第三方增强库
由于Go的切片提供的方法非常少, 因此使用起来远没有Java和Python中顺手, 为此可以使用一些第三方库增强切片的功能. 例如github.com/feyeleanor/slices库对于所有的基本类型和一般类型提供了大量简便方法, 例如插入, 删除, 查找, 替换和常见的谓词操作.
1 | import ( |
不过从实际开发角度来说, GO语言一般不太涉及对Slice的复杂的原地操作, 因此一般手写一个for循环也足够应付大部分开发场景了.
切片与内存泄露
由于切片是底层数组的一个引用, 因此即使只有非常小的一个切片引用, 也会导致整个底层数组无法被释放. 如果不想出现这种问题, 可以考虑在返回切片的时候创建一个切片的拷贝, 从而切断与原始底层数组的联系.
此外, 与Java实现堆栈的情形类似, 如果切片中持有了对象的指针, 而删除指针的时候没有手动置为null, 也会导致对象被延迟垃圾回收.
不过实际上这是一个生命周期问题, 当代码中涉及长期持有对象时, 就需要考虑所有引用的问题. 而如果仅仅是短期使用, 则不需要担心这些问题了.
哈希表
Go语言中使用内置的map实现哈希表结构. 其内部结构如图所示:
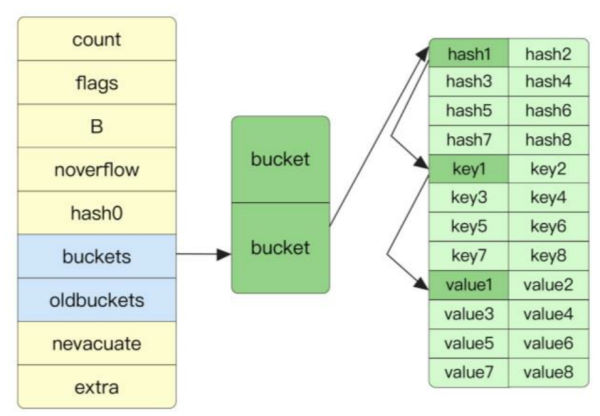
在map结构中, buckets字段指向了一个桶的数组. 其中每个桶可存储8个元素. 在桶内为了充分保证字节对齐, key和value是分开存储的. 因为Go在编译阶段已经可以得知key和value的具体类型, 因此可通过类型计算出key和value的具体偏移值.
与许多语言存储元素的方式不同, GO语言中根据Hash值的低位确定应该使用那一个桶. 低位相同的元素存储在同一个桶中, 因此每个桶实际上可以存储至多8个Hash值低位相同的元素. 当桶中元素超过8个时, buckets使用一个overflow指针指向一个新的 buckets对象, 从而实现其他语言中类似链表的冲突解决方案.
Go语言的负载因子定义为哈希表元素数量/桶数量, 并且在负载因子达到6.5时触发扩容. 扩容过程类似于Redis的渐进式Rehash, 在扩容时并不会立即移动所有元素, 而是将移动操作平均到各种操作之中
思考: 为什么GO采用与其他语言显著不同的实现方式? 该实现具有什么好处?
- GO语言使用桶的方式进行存储, 使得数据存储更加紧凑, 存储相同数量的元素时, 内存占用明显小于其他语言的实现.
- 在一个桶中存储多个元素的方式可以充分地利用局部性, 使得大部分数据可在CPU缓存中读取.
可以直接使用列表初始化一个map, 也可以使用make函数创建map. 使用make函数时能够提前分配空间, 从而减少扩容操作产生的性能消耗.
1 | // 直接列表初始化 |
map会自动扩容, 但创建时设置一个合适的初始值有助于减少扩容的性能消耗. 使用make函数创建map时, 其容量字段表示的含义是该map至少可以容纳指定数量的元素且不产生扩容. 因此实际分配的空间将取决于初始值和装载因子等参数.
map是引用类型, 因此传递map对象并不会导致内部储存数据的复制. 但map对象本身具有结构, 因此也不可将其直接视为一个指针.
注意: map类型必须初始化, 否则直接添加数据会导致空指针错误
由于map中能够存储任意类型的数据, 因此获取数据时可以采用如下的两种方式
1 | // 如果数据不存在返回对应类型的零值, 如果本身就是零值, 也会返回零值 |
随机遍历顺序
Go语言底层对map做了随机化处理, 每次遍历map时都是无序的, 从而避免开发者将map当做有序容器使用. 具体实现包括
- 每个map创建时初始化一个随机数种子, 该种子参与哈希值计算, 从而确保一个key在不同的map中哈希桶位置不同
- 每次开始遍历时, 随机选择一个起始位置开始遍历, 从而保证每次遍历的初始值不同
每次遍历得到的序列并不相同, 但仅仅是起点不同, 并不是顺序完全不同. 这种方案给遍历带来了随机性的同时又不会产生太大的性能开销.
零值可用性
不同于切片在任何时候都是零值可用, map数据的零值具有不同的表现, 建议始终使用make函数创建map而不要依赖零值可用性.
1 | var m map[string]string |
切片是一个比较简单的引用类型的数据结构, 而map是一个相对较重的数据结构, 因此GO语言的map必须手动初始化.
IO操作
与Java的抽象一样, Go也提供了一套统一的IO操作, 无论是读写文件, 读写网络数据, 读写标准输入输出还是读写字符串, 都可以抽象为对应的IO读写操作, 基于IO接口的上层函数也可以应用到任意的一种实现了IO接口的数据类型上. Go语言中定义了两个基本的IO接口, 即
1 | type Reader interface { |
注意: Read方法的err可能会返回io.EOF, 进行错误处理时需要对该情况进行额外处理
后续的很多方法都将Reader或者Writer对象作为操作的参数, 常见的实现了上述接口的对象如下表所示
| 类型 | 创建方法 | 备注 |
|---|---|---|
| os.File | os.Open/OpenFile | 文件类型实现了Reader和Writer等方法 |
| strings.Reader | strings.NewReader | 将一个字符串转换为一个Reader |
| bufio.Reader/Writer | bufio.NewReader | 将一个Reader转化为一个带缓冲的Reader |
| bytes.Buffer | bytes.NewBuffer | 创建一个字节缓冲区或者从字符串构造一个缓冲区 |
| bytes.Reader/Writer | bytes.NewReader | 将一个字节数组转换为一个Reader |
| net/conn | 网络相关方法 | 网络流也实现了了Reader和Writer等方法 |
扩展接口
除了最基础的读取和写入接口外, 在io包中还定义了如下的一些接口, 其含义都非常明确
1 | type ReaderFrom interface { |
通常情况下, 由Writer对象实现ReadFrom方法, Reader对象实现WriteTo方法, 从而将一个IO流中的数据全部移动到另一个IO流中. 某些自定义的数据结构也可以使用该方法表示读取或写入全部数据.
读取整个文件
对于读取或者写入全部的数据, ioutil包提供了如下的方法
1 | func ReadFile(filename string) ([]byte, error) |
按行读取文件
如果需要按行读取数据, 可以执行
1 | f, _ := os.Open("Hello.go") |
或者
1 | f, _ := os.Open("Hello.go") |
bufio的Reader对象还提供了一些有帮助的简化方法, 例如
1 | func (b *Reader) ReadSlice(delim byte) (line []byte, err error) |
读取全部数据
ioutil包提供了如下的方法从任意Reader读取全部数据
1 | func ReadAll(r io.Reader) ([]byte, error) |
格式化输入输出
Go的格式化系统与C基本一致, 对于文件, 标准输入输出和字符串提供了格式化函数, 并且使用一套类似的占位符, 具体如下
| 类型 | 可选占位符 | 备注 |
|---|---|---|
| 一般占位符 | %v %T | 使用Go格式输出, 通常用于复合结构 |
| 布尔值 | %t | 输出布尔值 |
| 整数 | %b %c %d %o %x %X %U | 除了各种进制以外, %U表示按照Unicode编码输出 |
| 浮点数和复数 | %b %e %E %f %g %G | %e表示使用科学计数法, %g表示视情况选择最短的表示方法 |
| 字符串 | %s %q %x %X | %q表示输出时添加一对引号 |
| 指针 | %p | 输出地址值 |
除了占位符以外, 其他标记包括
| 其他标记 | 含义 |
|---|---|
| + | 始终打印数值的正负号 |
| - | 左对齐 |
| # | 添加前导符号(例如16进制添加0x) |
| (空格) | 使用空格填充空位 |
| 0 | 使用0填充空位 |
此外, 对于最常用的一般占位符, %v仅打印结构体的值, 而%+v会打印结构体的字段名和结构体的值. 可以根据需要选择简略模式还是详细模式.
使用常量字符串进行格式化
对于类似 Fprintf(w io.Writer, format string, a ...any)这样的函数, format参数是一个字符串, 其中支持使用上面提到的符号. 为了避免产生注入问题, 一般要求该字段是一个常量, 即
1 | // 正确: 使用明确的常量字符串进行格式化空值 |
在错误用法中, 如果userMsg中正好包含了%d之类的字符串, 则会被当做一个占位符进行处理, 虽然在Go语言中不会因此产生内存安全问题, 但可能导致错误的格式化输出.
字符串操作
Go本身并不暴露string的底层结构, 但可以认为Go语言中的字符串与C的实现类似, 是一个指向实际数据的指针. 和大部分语言一样, string也是不可变的, 传递string变量也不会产生拷贝开销.
由于字符串本身具有结构, 因此无法直接将一个nil指针转换为一个空字符串. 实际上该操作会直接导致panic, 但通过类型转换的方式可以得到空字符串, 例如 string(nil) == “”
strings包提供了字符串的常见操作, 包括比较字符串大小, 查找字符, 替换字符, 合并字符串等操作
字符串转数字
strconv包提供了字符串到数值的转换, 例如字符串转整数, 字符串转浮点数等. strconv包定义了两种常见的错误, 即strconv.ErrRange表示转换超出表示范围, strconv.ErrSyntax表示要转换的数据不符合对应的格式.
1 | func ParseInt(s string, base int, bitSize int) (i int64, err error) |
base是数据的进制, 例如2进制, 10进制, 16进制. bitSize表示数据的长度, 例如8表示转换为int8. 如果bitSize取零, 表示转换为平台使用的int对应的长度.
Atoi 相当于 ParseInt(s, 10, 0)
整型转为字符串
1 | func FormatUint(i uint64, base int) string // 无符号整型转字符串 |
Itoa 相当于 FormatInt(i, 10)
字符串与字节数组的转换
对于字符串和字节数组的转化, Go提供了标准操作, 代码如下
1 | var str string = "test" |
由于字符串不可变, 因此在转换过程中需要对内容进行一次拷贝.
对于极端需要性能的场景, 存在如下的转换方法.
1 | func String2Bytes(s string) []byte { |
由于调用了unsafe方法, 因此代码存在安全问题, 通常情况下都不应该使用该方法进行转换.
此外, 对于Gin项目中, 使用了如下的方式进行转换
1 | func StringToBytes(s string) []byte { |
上述代码抛弃了reflect库的API, 因此兼容性可能会更好一点. 但是代码依然假定了Go底层的实现结构, 如果Go内部实现发生变化将导致上述代码无法执行.
interface结构原理
在泛型或反射场景中经常使用interface{}表示任意类型的变量, 但是由于Go语言对interface{}的实现, interface{}实际上并不与C中的void*或者Java中的Object等价.
针对一个接口是否定义了方法, 接口变量可能有两种实现. 包含方法的iface和不包含方法的eface. 以eface为例, 对应的实例变量的结构可以视为
1 | type eface struct { |
其中_type存储了实际变量的类型, data存储了实际变量的值, 例如对于如下的代码
1 |
|
对num和face进行nil判断会得到不同的结果. 其本质原因就是face变量并非一个指向num的指针, 而是具有自己的内存结构, 虽然data部分为nil, 但_type部分存储了num的类型.
interface{}常用于反射, 因此显然其中也需要存储原始指向的变量的类型.
显然, face变量与num变量的内存结构是不同的, 因此赋值操作也不是简单的内存拷贝, 而是需要根据变量的类型合适的设置face的值. 与C/Java中等号永远是简单赋值操作不同, Go有点类似C++, 在不同的场景下等号会进行适当的重载.
从而可以得到一个显然的结论, 使用interface赋值不是原子的. 原子包中提供了对任意类型的原子赋值能力.
时间包
程序中应使用 Time 类型值来保存和传递时间. 使用Before, After和Equal等方法进行比较和运算. 使用Sub方法可以获取两个时间的差值, 生成一个Duration对象.
反射操作包
反射操作包的核心是两个函数reflect.TypeOf和reflect.ValueOf, 两个函数都可以接受任意的变量, 分别返回变量的类型和变量实际的值. 例如
1 | mm := make(map[string]string, 23) |
似乎看起来reflect.ValueOf这种获得变量的值的操作并没有意义, 因为直接访问变量也能获得变量的值. 但需要注意到, 使用反射场景的时候, 给定的参数通常是表示任意类型的interface{}, 虽然其中存储了变量实际的值, 但空接口并不提供获得底层值的方法. 以下代码演示了如何根据reflect.Value获得变量实际的值
1 | // formatAtom formats a value without inspecting its internal structure. |
反射存在运行时产生painc, 性能低下等问题, 因此通常情况下不要使用反射
原子操作
在GO语言中, 对于小于64位的基本类型和指针类型, 其赋值操作是原子的, 可以不加锁的进行并发赋值. 但对于复杂的数据结构, 无法保证原子的赋值. Go提供了Value对象来原子的对任意类型赋值. 其Store函数源码如下:
1 | func (v *Value) Store(val any) { |
上述接口非常巧妙地利用了Go语言中interface{}对象的结构, 用一种简单的方式实现了对象的原子赋值
IP操作
解析IP地址
1 | parsedIP := net.ParseIP(rawIP) |
使用net.ParseIP可以将一个字符串格式的IP地址解析为Go语言中的IP对象. IP对象实际是一个字节数组, 通常占据16字节(对应IPV6地址的长度), 采用大端序存储IP的字节.
注意: 根据IP协议的规范, 任何一个合法的IPV4地址也是一个合法的IPV6地址. 不要根据IP对象的长度判断IP类型
数据库操作
Go语言在标准库database/sql包中提供了数据库相关的操作. 在database/sql包中并未实现具体的数据库操作, 而是给出了一组关于driver的接口, 所有关于数据库的操作最终均通过操作driver的接口实现. 通过在代码中注册不同的数据库driver, 从而实现连接到不同的数据库.
创建连接
database/sql包中的核心对象是DB结构体. DB表示了拥有一个或多个连接的连接池. 实际上, 相较于Java/C++等语言, Go语言似乎因为出现的比较晚, 因此DB默认就是一个连接池. 不同版本的Go对于database/sql包的实现基本一致.
设置连接池大小
除非数据库操作频率非常低, 否则始终应该设置连接池大小. 在未设置连接池大小的情况下, 创建过多的连接可能导致数据库服务消耗更多的CPU, 导致新增连接失败或者干扰其他业务.
在设置了连接池大小的情况下, 如果当前无法从连接池获取一个可用链接, 则当前协程会阻塞, 直到获得可用链接后再继续执行. 当一个连接归还到连接处时, 会判断当前空闲连接数, 如果大于最大空闲连接数, 则释放当前连接.
评估数据库性能
对于云数据库, 可通过最大连接数与IOPS评估数据库性能. 例如在腾讯云中, 最低配置的1核1G数据库, 其IOPS标注为1200, 最大连接数为750. 则对于该数据库, 则最多可支持750个连接, 每秒钟可执行1200次IO操作.(对于写入数据而言, 基本约等于写入速度)
根据业务逻辑的机器数量可计算每台机器允许的最大连接数. 例如当前有10台机器需要连接该数据库, 则每台机器至多使用75个连接. 考虑到其他服务可能也需要连接该数据库以及服务器本身的性能, 则实际允许的最大连接数量则还要明显小于75.
通过最大连接数, 可以一定程度的限制单台机器的写入速度. 例如当前最大连接数设置为35, 则即使使用5000个协程进行写入操作, 对于数据库而言, 依然相当于35个连接在发送请求. 5000个协程在写入数据时, 需要排队进行写入.
数据库的写入性能最终还是取决于IOPS, 如果50个连接就可以使IOPS达到最大值, 那么新增更多连接也不会使插入速度更快, 过多的连接数还会导致数据库消耗更多CPU用于链接处理, 导致数据库性能下降.
扩展阅读
singleflight包
singleflight包提供了一个Do函数, 用于防止在短时间内对同一组参数的重复调用. Do函数根据传入的key来判断是否需要执行函数f, 如果多个协程同时调用Do函数并具有相同的key, 则只有1个协程会实际调用f, 其他函数会阻塞等待f执行结束, 并且所有的协程获得相同的值.
singleflight包提供的能力对于防止缓存击穿等问题特别有用
想要实现上述效果其思路非常直接, 使用一个map存储key和执行结果. 执行Do函数时首先判断map中是否有对应的结构体, 如果存在则说明此时有另外一个协程在执行, 因此使用WaitGroup进行等待. 如果map中无对应结构体, 则使用WaitGroup进行Add(1)操作, 然后调用f. f执行完毕后, 执行WaitGroup的Done操作, 唤醒等待的其他协程.
1 | func (g *Group) Do(key string, fn func() (interface{}, error)) (v interface{}, err error, shared bool) { |
文件嵌入
GO语言可将任意文件在编译时嵌入二进制文件中, 并提供一些接口像直接访问文件系统一样读取这些嵌入的文件. 使用这一方法可以将一些资源文件和代码打包到一起, 从而实现单一文件即可分发的效果.
嵌入单个文件
1 | package main |
在注释中使用go:embed指定需要嵌入的文件. 之后可以直接访问这个变量, Go会自动将变量填充为文件的内容.
嵌入多个文件
1 | package main |
嵌入多个文件时, 相当于内置了一个文件系统, 可以按照文件系统的方式读取这些文件.
手动指定DNS服务
通常情况下Go关于网络的操作使用C语言相关的库, 从而在不同的操作系统中使用各自的实现. 但如果使用交叉编译, 则会禁用CGO特性, 改为使用纯GO实现. 纯GO实现对于各种细节的支持远低于C语言库, 因此偶尔会出现各类异常情况. 此时可以手动设置DNS服务器, 绕过本地操作系统的问题. 具体代码为
1 | package main |
参考资料与扩展阅读
最后更新: 2026年07月25日 12:35
版权声明:本文为原创文章,转载请注明出处