- 汇编格式差异
- 指令后缀
- 寄存器结构
- 操作数指示符
- 数据传送指令
- 栈操作
- 算数指令
- 条件码
- 过程
- 对抗缓冲区溢出攻击
- 浮点体系结构
- 扩展:为什么浮点运算寄存器数量更多
- 扩展:为什么SSE/AVX向量指令可以加速数据复制
- 浮点数操作
汇编格式差异
对于GCC编译器, 其汇编代码默认AT&T格式. 通常情况下, 计算机的汇编语言课程仅讲解Intel格式的汇编代码, 因此对于AT&T格式可能较为陌生. 两种格式的主要区别如下:
| 区别 | Intel格式 | AT&T格式 | 说明 |
|---|---|---|---|
| 寄存器 | eax | %eax | Intel格式无前缀, AT&T格式始终使用%前缀 |
| 立即数 | 6 | $6 | Intel格式中数字就是数字 |
| 内存地址 | [0x1234] | 0x1234 | AT&T格式格式中数字默认是地址 |
| 操作数大小 | 使用数据类型修饰符 | 指令后最后一个字母 | mov byte[0x123], eax movb eax, 0x123 |
两种格式的主要差别如下:
- 在Intel格式中, 指令顺序为
op dst, src. AT&T格式相反, 为op src, dst - 在Intel格式中, 数字就是立即数, 如果表示内存地址, 需要使用
[]. 而AT&T格式相反, 数字就是内存地址, 如果表示立即数, 需要使用$前缀.
指令后缀
与X86汇编相比, X64汇编的一个显著区别是增加了对64bit数据的操作, 对于所有的数据传输指令, 都可以添加指令后缀来明确具体数据的具体长度, 后缀的关系如下表所示
| C语言声明 | Intel数据类型 | 汇编后缀 | 字节长度 |
|---|---|---|---|
| char | 字节(byte) | b | 1 |
| short | 字(word) | w | 2 |
| int | 双字(double word) | l | 4 |
| long | 四字(quad word) | q | 8 |
| char* | 四字(quad word) | q | 8 |
| float | 单精度(single) | s | 4 |
| double | 双精度(double) | l | 8 |
双字使用l作为后缀, 因此双字也被认为是一种长字节(long word). 浮点数指令和整数指令后缀有一些冲突, 但实际上由于浮点数指令是一套单独的指令, 因此并不会构成冲突.
寄存器结构
X64寄存器数量和寄存器长度都在X86的基础上再次翻倍, 每个寄存器都是64位长度, 并且新加入的8个寄存器, 新加入的寄存器分别命名为%r8~%r15. 所有寄存器和使用规则如下表所示
| 寄存器 | 使用规则 | 寄存器 | 使用规则 |
|---|---|---|---|
| %rax | 返回值 | %r8 | 第5个参数 |
| %rbx | 被调用者保存 | %r9 | 第6个参数 |
| %rcx | 第4个参数 | %r10 | 调用者保存 |
| %rdx | 第3个参数 | %r11 | 调用者保存 |
| %rsi | 第2个参数 | %r12 | 被调用者保存 |
| %rdi | 第1个参数 | %r13 | 被调用者保存 |
| %rbp | 被调用者保存 | %r14 | 被调用者保存 |
| %rps | 栈指针 | %r15 | 被调用者保存 |
与X86汇编一样, 可以通过类似%eax, %ax, %ah, %al的方式访问原有的8个寄存器的低位部分. 对于新增的寄存器, 也可以使用类似%r8d, %r8w, %r8b的方式访问r8寄存器的低32位, 低16位和低8位.
由于寄存器数量有明显的增加, 因此与X86相比, 一个显著的变化就是大部分时候的函数调用不需要再进行参数入栈的操作, 大部分时候函数调用的参数都可以直接用寄存器传递.
将数据移动到寄存器时, 如果移动的数据是1字节或2字节, 则寄存器的高位不变. 如果移动的数据是4字节, 则将高位数据置零
操作数指示符
| 格式 | 名称 | 格式 | 名称 |
|---|---|---|---|
$0x1234 |
立即数 | %rax |
取%rax的值 |
0x1234 |
绝对寻址 | (%rax) |
取%rax对应内存 |
-4(%rbx) |
取%rax加上偏移的内存值 | 12(%rbx, %rax) |
取寄存器与立即数之和的内存地址 |
数据传送指令
mov指令结合四种长度后缀可以表示四种不同长度的数据传输指令, 即movb, movw, movl和movq. mov指令既可以在寄存器之间传送数据, 也可以将立即数传入寄存器. 但movq指令只能接受32位的有符号立即数, 将其进行符号扩展到64位, 并传入寄存器. 如果需要传送64位立即数, 则需要使用movabsq指令进行绝对传送.
mov指令有两种变形, 分别是movz和movs. 两个指令分别表示零扩展和符号扩展. 例如movzbl表示将一个字节的数据先进行零扩展变为一个双字长度, 然后传送到目标位置, movzwq表示将一个字长度的数据进行零扩展变成四字长度后传送到目标位置.
数据传送指令虽然指定了数据的长度, 但不能与操作的寄存器发生冲突. 例如movl %rax, (%rbx) 似乎希望传送%rax的两个字节到内存, 但并没有这种用法, 如果需要传送低位, 只能使用%eax替换.
cltq指令是movslq %eax %rax指令的简化指令, 表示将%eax的数据符号扩展到%rax
栈操作
栈操作与X86汇编没有太大区别, 只是入栈和出栈的基本单元的大小都设置为8字节.
| 指令 | 效果 |
|---|---|
| pushq S | 将指定数据入栈 |
| popq D | 将栈中数据弹入指定寄存器 |
算数指令
大部分指令在加上后缀后都有四个版本, 例如addb, addw, addl和addq. 后缀含义都是一致的, 因此下面使用大写表示指令不包含后缀的部分
| 指令 | 含义 |
|---|---|
| leaq | 加载有效地址 |
| INC / DEC | 加减一 |
| NEG / NOT | 取负/取反 |
| ADD/SUB/IMUL | 加/减/乘 运算 |
| XOR/OR/AND | 异或/或/与 操作 |
| SAL/SHL | 算数左移 / 逻辑左移 |
| SAR / SHR | 算数右移 / 逻辑右移 |
SHR -> SHift RightSAR -> Shift Arithmetic Right
leaq指令表示加载变量的地址, 第一个操作数是一个内存位置, leaq指令将该内存位置的地址写入第二个参数.
由于地址表示有多种方式, 因此leaq指令相当于一个简易的算数运算器, 可以高效地执行特定的加法与乘法的组合, 因此可实现特定的计算, 例如如下的C语言代码,
1 | long scale(long x, long y, long z) { |
在O2优化等级下, 其汇编代码核心逻辑如下
1 | leaq (%rdi,%rsi,4), %rax ; x + 4 * y |
根据函数传参规则有 %rdi -> x; %rsi -> y; %rdx -> z, 可以很容易的验证上述汇编代码与原始的C代码逻辑一致.
编译器的优化能力果真是难以置信
条件码
CPU维护如下的一些条件码, 这些条件码均指示最近一次操作的一些特征, 具体如下
| 名称 | 含义 | 效果 |
|---|---|---|
| CF | 进位标志 | 是否产生进位 |
| ZF | 零标志 | 是否产生0 |
| SF | 符号标志 | 是否产生负数 |
| OF | 溢出标志 | 是否产生补码溢出 |
针对上述标志, 有两个常用的指令
| 指令 | 含义 | 解释 |
|---|---|---|
| CMP S1, S2 | S2 - S1 | 比较 |
| TEST S1, S2 | S1 & S2 | 测试 |
执行上述的操作后, 可使用SET指令设置结果, 或者使用JMP系列指令执行跳转. SET指令和JMP系列指令包含如下的一些后缀
| 类型 | 无符号 | 有符号 |
|---|---|---|
| 相等 | e(equal) | e(equal) |
| 大于 | a(abve) | l(less) |
| 小于 | b(below) | g(greater) |
| 否定 | n(not) | n(not) |
| 符号 | s(负数) | ns(非负) |
例如setl, setb, 或者je, jae
有时会看到编译器生成
repz retq指令, 该指令的作用是避免跳转指令的下一条指令直接是ret指令, 这种情况会导致处理器无法正确的实现分支预测, 从而降低性能.
过程
在x86-64体系之中, 函数调用的栈帧结构与x86-32有所不同, 具体如下图所示
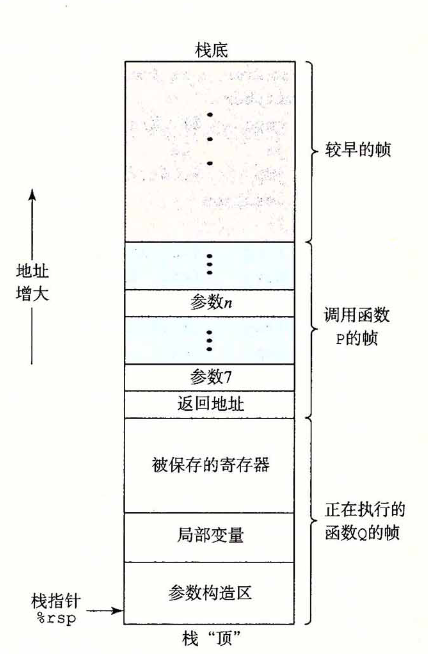
由于寄存器数量更多, 因此函数的前6个参数可直接使用寄存器传递, 从第7个参数开始才需要通过栈传递.
此外, 由于调用的规范, %rbx, %rbp和%r12~`%r15`属于被调用者保存寄存器, 因此被调用者要么完全不修改这些寄存器, 要么在修改前保存它们的值, 并在返回前恢复这些寄存器的值.
对抗缓冲区溢出攻击
如果程序没有正确的处理缓冲区的大小问题, 可能导致用户的输入覆盖了栈帧的返回地址, 进而导致程序跳转到攻击者指定的位置. 针对上述问题, 有一些对抗方案:
栈随机化. 由于攻击者既要插入恶意代码, 又要插入恶意代码的地址, 因此攻击者需要知道恶意代码的内存位置. 栈随机化通过每次在程序运行前, 随机分配一段不使用的空间, 使得每次运行时栈起始位置产生变化.
栈随机化已经是Linux的标准行为, 并且是地址空间布局随机化(Address-Space Layout Randomization, ASLR)技术的一个子类. 使用ASLR, 每次运行程序时, 程序的代码段, 栈, 全局变量, 栈都会加载到不同的位置.
栈破坏检测. 编译器在栈的缓冲区和返回地址之间插入一段特殊值(被称为金丝雀canary), 该数据在程序运行时随机产生, 并且在函数返回前检查是否被修改.
限制可执行代码区域. 在x86体系中, 可读和可执行使用同一标志位, 由于栈段必须是可读可写的, 因此其中的内容也是可执行的. 最近的CPU中, 引入了NX(No-Execute, 不可执行)位, 通过该标记, 可将栈段设置为可读可写不可执行, 从而由硬件检查是否满足要求.
浮点体系结构
浮点数指令集有两个常见的指令级, 即SSE(Steaming SIMDExtension)指令集与AVX(Advance Vector Extension)指令级. SEE中的寄存器称为XMM, 具有128位. AVX中的寄存器称为YMM, 具有256位.
两个指令集均提供16个寄存器, 分别为%xmm1 ~ %xmm15和%ymm1 ~ %ymm15. XMM寄存器可视为YMM寄存器的低位部分.
前8个寄存器可用于函数传参, 所有的寄存器均为调用者保存.
AVX-512支持 16 个或 32 个全新的 512-bit ZMM 寄存器, 并将原有的 YMM 寄存器进一步扩展为 ZMM 的低位部分. (笑死, 再扩展一下字母要不够用了)
扩展:为什么浮点运算寄存器数量更多
实现 SSE 和 AVX 指令集需要增加相当大的一块芯片面积, 虽然其中绝大部分是逻辑电路, 但寄存器数量也相比X86的传统寄存器数量多得多. 既然从物理上可以做到更大和更多的寄存器, 为什么X86指令还是只有16个64位寄存器呢?
x86 指令使用一种非常紧凑且复杂的变长编码格式, 表示寄存器的部分通常只占用 3 位, 即最多表示八个寄存器(AX, BX, CX, DX, SI, DI, BP, SP). 当从 32 位扩展到 64 位时, AMD在指令编码中引入了一个新的前缀字节(REX prefix), 这个前缀中包含了一位扩展位, 与原来指令中的 3 位寄存器字段结合形成了 4 位的寻址空间, 从而可以寻址 16 个寄存器.
如果再次扩展寻址范围, 需要进一步增加指令长度, 这可能导致二进制文件体积显著增加, 降低L1缓存中的指令数量, 减少缓存命中率. 对X86解码核心模块的修改也可能进一步增加复杂度. 这些因素叠加到一起可能完全抵消增加寄存器带来的效率提升甚至产生性能退步. 因此X86-64指令集几乎不可能再扩展寄存器数量了.
与此相对的, ARM指令集不需要考虑这些历史问题, 因此AArch64具有31个64位寄存器(X0到X31). 虽然无需考虑历史包袱, 但寄存器数量也并非越多越好. 寄存器数量过多依然会挤占指令的空间(ARM使用32bit固定长度指令), 削弱指令集的表达能力. 同时进程切换时, 寄存器越多, 需要保存的上下文也越多. 对于频繁进行切换的现代操作系统而言, 也需要在传递参数效率和切换效率之间找到一个平衡点.
ARM指令集的31个寄存器是有讲究的. 实际上第32个寄存器的编码在ARM指令集中被表示为零寄存器ZR(一个无论读写永远保持0的特殊寄存器)或者是栈指针寄存器(SP). 通过零寄存器可以进一步的压缩指令数量, 例如对于MOV Xd, Xm指令(寄存器到寄存器), 实际会被翻译为ORR Xd, XZR, Xm(将零寄存器 XZR 和源寄存器 Xm 进行逻辑或 ORR 操作,结果存入目标寄存器 Xd), 从而使ARM指令集中不需要单独提供一条MOV指令.
这种设计与X86指令集有显著差别, 也是非常能体验RISC和CISC的区别的例子.
扩展:为什么SSE/AVX向量指令可以加速数据复制
SSE/AVX向量指令能够加速数据复制的核心原因是一次可以读取更多字节的数据. RAX寄存器只能存储8字节数据, 而XMM可以存储16字节, YMM可以存储32字节, ZMM可以存储64字节. 因此SSE/AVX向量指令能使用更少的指令读取更多的数据.
此外, 使用向量指令可以更充分的利用内存的带宽, 更少的指令可以降低解码模块的压力, 大批量的数据读取可以使硬件预取器更容易提前准备数据, 提高缓存命中率. SSE/AVX指令集还提供了一些不写入缓存的指令(例如MOVNTDQ), 对于数据复制场景, 写入的数据短时间内通常不会立即访问, 因此不写入缓存也可以避免缓存污染.
浮点数操作
使用movss或者movsd在寄存器和内存中移动数据, 其中movss表示Move Scalar Single之类的意思. 如果需要在寄存器之间复制数据, 则需要使用movaps之类的指令, 其中a表示aligned
1 | float float_mov(float v1, float *src, float *dst) { |
1 | movaps %xmm0, %xmm1 |
浮点算数操作指令与整数操作基本相同, 但使用ss后缀, 例如addss, 对于如下的C代码
1 | double funct(double a, float x, float b, int i) { return a * x - b / i; } |
产生的汇编指令为
1 | cvtss2sd %xmm1, %xmm1 |
cvtss2sd将x转换为双精度浮点数, mulsd将a与x相乘. pxor清空%xmm0, 为后续做准备.
cvtsi2ssl将i转换为单精度浮点数, divss计算b与i的除法, cvtss2sd将除法结果转换为双精度浮点数
subsd执行双精度浮点数减法, movapd执行寄存器赋值.
可以看到浮点指令集基本与整数指令集对应
浮点指令中无法使用立即数, 必须先将对应的数字写入内存, 在从内存加载到寄存器
最后更新: 2026年07月20日 15:35
版权声明:本文为原创文章,转载请注明出处
原始链接: https://lizec.top/2020/08/10/CSAPP%E7%AC%94%E8%AE%B0%E4%B9%8B%E6%B1%87%E7%BC%96%E8%AF%AD%E8%A8%80/