本文是大数据分析案例系列文章. 本文主要介绍将前一步生成的数据导入Hadoop平台,并进一步将数据导入Hive. 数据导入以后,可以使用SQL语句进行查询和分析, 最后对比统计分析结果和之前随机数的使用结果.
数据导入Hadoop
启动Hadoop
在Hadoop安装目录下执行
1 | sbin/start-dfs.sh |
访问 http://localhost:9870/, 如果显示正常, 则说明hdfs启动成功.
导入数据
在Hadoop安装目录下执行
1 | bin/hdfs dfs -mkdir -p /dataset/user |
从而在HDFS的根目录下创建一个dataset文件夹, 之后可以在 HDFS提供的Web版文件浏览器中查看是否创建成功. 导入文件之后,也可以使用文件浏览器查看导入文件的情况.
假设前一步生成的数据存放在 /home/lizec/IdeaProjects/RandomDataSet/data.txt, 则在Hadoop安装目录下执行
1 | bin/hdfs dfs -put /home/lizec/IdeaProjects/RandomDataSet/data.txt /dataset/user/user.txt |
将本地文件系统中的data.txt文件复制到Hadoop文件系统之中,并且命名为user.txt. 在文件浏览器中查看无误, 则数据以及成功导入到HDFS之中.
关于HDFS的Shell指令,可以查看HDFS Commands Guide. 实际上, 很多指令都与linux本身的shell指令相类似, 如果有shell的使用经验, 可以很容易的理解上述的指令.
数据导入Hive
启动Hive
在Hive安装目录下执行
1 | bin/hive |
启动后Hive给出了输出, 提示基于MapReduce的Hive在Hive 2中已经被标记为废弃, 后续可能不再支持, 建议更换引擎(例如Spark), 或者继续使用Hive 1
因此虽然已经被废弃,但是继续使用是暂时没有问题的, 关于更换引擎的问题,后续有机会再补充.
导入数据
Hive启动后, 先输入以下的HiveQL语句来创建数据库
1 | CREATE DATABASE bigdata; |
然后执行下面的语句创建表
1 | CREATE EXTERNAL TABLE bigdata.userinfo( |
这里解释一下上面的语句, 前面的CREATE操作和SQL一样,创建了一个表dblab.user,其中有若干字段. COMMENT行是表的注释. ROW FORMAT DELIMITED表示将源文件中的每一行视为一条记录, FIELDS TERMINATED BY ' '表示以空格作为分隔符切分字段. STORED AS TEXTFILE表示以文本形式存储. LOCATION '/dataset/user/'指定原始数据在HDFS中的路径,该路径下所有的文件都为视为原始数据.
此外user似乎是关键字, 不能作为表的名称.
数据分析
基本信息
首先可以查看表的前10条数据,来确保数据已经被正确的解析, 执行如下的语句:
1 | select * from userinfo limit 10; |
返回结果如下
1 | OK |
由此可见,数据已经被正确的解析,并且可以通过sql语句进行查询.
数据分布检验
省份数据检验
在前一步的数据生成过程中,对省份的数据进行了特殊的处理,使得各省份出现的概率与该省份的人口数量成正比. 下面通过统计检验这一设定是否成立.
通过统计各个省份实际出现的次数,并且依据次数的多少进行排名,再与实际的人口排名进行对比, 即可简单的检验设定是否正确. 因此执行如下语句统计各个省份实际出现的次数
1 | SELECT province, COUNT(*) num FROM userinfo GROUP BY province ORDER BY num DESC LIMIT 10; |
统计得到结果如下
1 | 广东省 182569 |
与之前的2018年全国各省人口总数排行榜进行比较,可以看到两者的结果是完全一致的,各部分之间比例也是接近的, 从而说明之前的随机算法是正确的.
数据导入MySQL
创建Hive表
经过前面的各种数据分析,我们可以把最后的分析结果导入到MySQL数据库中,从而可以被其他应用程序访问和展示. 首先在Hive中创建一个省份的分布表,并向其中插入数据, 代码如下:
1 | CREATE TABLE bigdata.prvinfo( |
其中第一部分的代码创建了一个名为prvinfo的表,其中包含省份名和数量两个字段. 第二部分代码之前已经使用过,从原始的表中分别统计了每个省份的人数.
上述代码执行完毕后, 可以使用HDFS的文件浏览器查看/user/hive/warehouse/bigdata.db/prvinfo目录下是否有创建文件,以及文件内容是否为上述指令的查询结果.
创建MySQL表
启动mysql,并且执行如下的语句:
1 | CREATE DATABASE bigdata; |
第一部分代码创建了一个数据库bigdata,第二部分代码创建了一个表prvinfo. 由于MySQL中并没有的STRING类型,因此可以使用CHAR代替.
使用Sqoop导入数据
这里使用的Sqoop是Sqoop1.4.7, 是当前的最新稳定版. 还有一个版本是Sqoop1.99.7, 根据官网介绍,这个版本与Sqoop1.4.7不兼容,不建议在生产环境中部署此版本.
在Sqoop的安装目录下执行以下指令:
1 | bin/sqoop export --connect jdbc:mysql://localhost:3306/bigdata --username root --password 123456 --table 'prvinfo' --export-dir '/user/hive/warehouse/bigdata.db/prvinfo' --fields-terminated-by '\t'; |
各参数含义如下
| 参数 | 含义 |
|---|---|
| connect | 需要连接的mysql数据库 |
| username | mysql用户名 |
| password | mysql密码 |
| table | 被导入的mysql数据库表名 |
| export-dir | Hive数据的HDFS路径 |
| fields-terminated-by | 数据分割符号 |
注意: --table 指定表名时, 表名一定要用引号括起来,否则可能导入失败.
数据可视化
在前一步, 我们已经将省份的数据导入了MySQL之中, 之后我们就可以使用Java Web的有关技术来获得数据并且在网页上展示出来. 这里使用Tomcat作为Web服务器, 使用ECharts作为数据可视化工具. ECharts是一个JavaScript编写的图像库, 可以简单地绘制各种常见图形.
环境配置
环境配置可以参考如下的一些文章, Tomcat和ECharts的配置都很简单,就不赘述了.
数据转换
把数据库中的数据绘制到网页上有三个步骤
- 使用Java语言将数据从数据库中取出
- 将JSP的数据转换为JS的数组
- 调用EChart的函数绘制图形
其中第一步和第三步都是常规操作, 这里简单介绍第二步的实现方案.
在JSP代码部分, 首先声明数组并且把数据填充为HTML代码:
1 | <!-- 声明存放数据的Java数组,并获得数据 --> |
接下来使用js的标签查找方式获得上述的标签, 然后取出各个标签的value字段
1 | var sname = document.getElementsByName("store_name") |
这样就完成了JSP数组到JS数组的转化, 由于本人没系统学过JS, 因此不能保证这种转化方案是最优的, 欢迎各位在评论区补充.
结果展示
对于省份数据, 可以考虑使用饼图进行展示. ECharts网站上提供了很多实例, 我们只需要稍加修改即可完成数据的展示, 例如选择Pie With Scollable Legend.
直接复制左侧的实例代码, 将其中的数据源修改为我们从数据库中提取的数据, 最终绘制结果如下所示
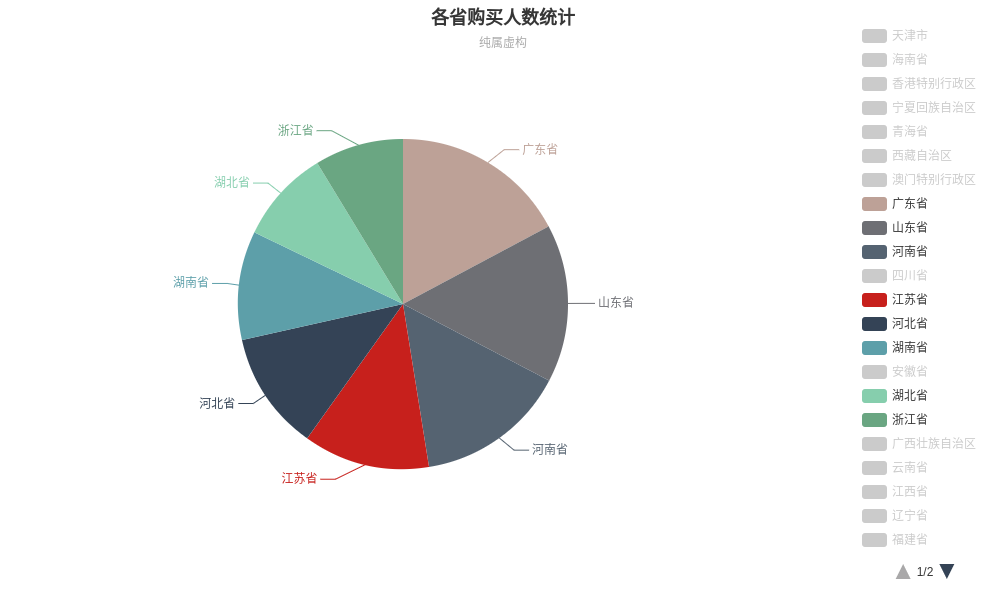
特别感谢
在本文的编写过程中, 参考了如下的两个系列的博客, 对博客的作者表示由衷地感谢!
参考资料
- Why do we use ‘row format delimited’ and ‘fields terminated by’ in table creation in Hive and in Hadoop?
- hive sql语法解读
- hive内部表与外部表区别详细介绍
最后更新: 2026年07月25日 12:35
版权声明:本文为原创文章,转载请注明出处