目录
## 第一章 绪论
人工智能(Artificial Intelligence, AI)
- 是一门综合性学科,它旨在研究如何利用计算机等现代工具设计模拟人类智能行为的系统
图灵测试(Turing Test)
- 在2000年之前,计算机有30%的概率蒙骗一个普通人达到5分钟
- 图灵测试仅反映了结果的比较,没有涉及视为过程,没有指出什么是人
三个主要学派
- 符号主义学派(逻辑主义, 心理学派)
- 主要观点: AI起源于数理逻辑,人类认知的基元是符号,认知过程是符号的表示上的一种运算
- 代表性成果: 厄尔和西蒙等人研制的称为逻辑理论机的数学定理证明程序LT
- 连接主义学派(仿生学派或心理学配)
- 主要观点: AI起源与仿生学,特别是人脑模型,人类认知的基元是神经元,认知过程是神经元的连接活动过程
- 代表性成果: 由麦克洛奇和皮兹创立的脑模型, 即MP模型
- 行为主义学派(进化主义,控制论学派)
- 主要观点: AI起源与控制论,只能取决于感知和行为,取决于对外界复杂环境的适应,而不是推理
- 代表性成果: Brooks教授研制的机器虫
人工智能研究和应用领域
- 定理证明
- 专家系统
- 机器学习
- 自然语言理解
- 智能检索
- 机器人学
- 自动程序设计
- 组合调度问题
- 模式识别
- 机器视觉
## 第二章 知识表示
一阶谓词的逻辑表示
- 是一种基于数理逻辑的表示方法
- 其基础是命题
命题
- 一个陈述句称为断言
- 具有真假意义的断言称为命题
谓词
- 是命题的谓语,表示个体的性质,状态或个体之间的关系
- 个体: 是命题的主语,表示独立存在的事物或概念
- 谓词与函数的区别
- 谓词是个体域D到{T,F}的映射
- 函数是个体域到个体域的映射
- 谓词可独立存在,函数只能作为谓词的个体
项
- 单独的一个个体词是项
- 若t1,t2,…,tn是项,f是n元函数,则f(t1,t2,…,tn)是项
- 有(1),(2)生成的表达式是项
- 项是个体常量,个体变量和函数的统一
原子谓词公式
- 若t1,t2,…,tn是项, P是谓词,则称P(t1,t2,…,tn)为原子谓词公式
一阶谓词等价式
- 吸收律
- 量词分配律
- 全体对且分配
- 存在对或分配
推理规则
- P规则
- 在任何的步骤上都可以引入前提
- T规则
- 在推理时,如果前面的步骤中有一个或多个公式永真蕴含S,则可把S引入推理过程
- CP规则
- 如果能从R和前提集合中推出S,则可从前提集合推出R->S
- 反证法规则
- 若P=>Q,当前仅当P且非Q不可满足
- 推广到有n个变元的情况,(P1,P2,…,Pn) => Q,当且仅当(P1,非P2,…,非Pn)且非Q不可满足
谓词逻辑表示方法
- 根据要表示的知识定义谓词
- 使用连词,量词把这些谓词连接起来
产生式表示法
- 确定性知识,事实可用三元组表示
- (对象,属性,值)
- 例如: (雪,颜色,白), (热爱,王峰,祖国)
- 非确定性知识,事实可用如下四元组表示
- (对象,属性,值,可行度因子)
规则的作用
- 描述事物之间的因果关系
- 基本形式
P -> Q或IF P THEN Q- 即,如果前提P满足,则可推出结论Q或执行Q所规定的操作
产生式与蕴含是的主要区别
- 蕴含式表示的知识只能是精确的,产生式表示的知识可以是不确定的
- 蕴含式的匹配一定要求是精确的,而产生式的匹配可以是不确定的
产生式系统
- 一个产生式系统由以下3个基本部分
1 | [规则库] <--> [控制机构] <--> [综合数据库] |
- 规则库(Rule Base, RB)
- 也称知识库(Knowledge Base,KB),用于存放求解问题有关的所有规则的集合
- 作用: 是产生式系统问题求解的基础
- 要求: 知识的完整性,一致性,准确性,灵活性和知识组织的合理性
- 控制机构
- 也称推理机,用于控制整个产生式系统的运行,确定问题求解的推理线路
- 主要任务包括: 选择匹配,冲突消解,执行操作,不确定推理,路径解释,终止推理
框架表示法
- 有若干接点和关系(统称为槽)构成的网络
- 是语义网络的一般化形式
- 没有固定的推理机理,遵循匹配和继承的原理
- 善于表示结构性的知识
## 第三章 搜索方法
表示方法
- 状态空间
- 用状态和算符来表示问题
- 状态
- 描述问题求解过程不同时刻的状态的数据结构,可用一组变量的有序集表示
- 当给每个分量一个确定值时,即得到了一个具体的状态
- 算符
- 引起状态中某些分量发生变化,从而使问题由一个状态变为另一个状态的操作
- 在产生式系统中,每条产生式规则就是一个算符
- 算符每次使用使状态发生改变,达到目标状态时,由初始状态到目标状态使用的算符序列就是问题的一个解
- 由问题的全部状态以及一些可用的算符构成的集合称为问题的状态空间
- 一般用一个三元组表示:(S,F,G)
- 其中S是问题的所有初始状态构成的集合,F是算符的集合,G是目标状态的集合
- 与或树
- 把复杂的问题转化为若干需要同时处理的较为简单的子问题后,分别求解
- 如果问题P可以归约为一组子问题P1,P2,…,Pn,并且当任意子问题Pi无解时,原问题无解
- 则称此归约为问题的分解
- 分解的子问题的与 同原问题等价,使用与树表示
- 如果问题P可以归约为一组子问题P1,P2,…,Pn,并且子问题Pi中所有的子问题都无解时,原问题才无解
- 则称此种归约为问题的等价变化
- 变换得到的子问题的或 同原问题等价,使用或树表示
- 本原问题
- 不能再分解或变换,而且可以直接可解的子问题
- 端结点与终止节点
- 没有子节点的节点称为端结点
- 本原问题对应的节点称为终止节点
- 终止节点一定是端结点,端结点不一定是终止节点
- 可解节点
- 满足以下条件之一的节点称为可解节点
- 是终止节点
- 是一个或节点,且子节点至少有一个可解
- 是一个与节点,且全部子节点都可解
状态空间的搜索方法
- 盲目搜索
- 数据结构
- OPEN表: 存放待考察的节点
- CLOSED表: 存放已考察的节点
- 搜索方法(盲目搜索)
- 宽度优先
- 非改进方法中,从OPEN表取出元素,判断是否是目标节点
- 改进方法中,在放入OPEN表前,判断是否是目标节点
- 深度优先
- 有界深度优先
- 设计搜索深度dm,当达到深度后就选择其他兄弟节点扩展
- 改进算法
- 先设置一个较小的dm,如果全部遍历后不能满足,且CLOSED表中还存在可扩展节点,那么将这些节点送回OPEN表,并扩大dm
- 重复上述操作直到问题求解
- 此方案不一定获得最优解
- 可以设置表R,记录搜索过程中得到的目标节点的路径长度,然后继续搜索
- 保证搜索的解的路径长度最短,则可以保证获得最优解
- 代价树的宽度优先搜索
- 边上标有代价的树称为代价树,使用g(x)表示从初始节点到节点x的代价
- 若c(x1,x2)表示从父节点x1到子节点x2的代价,则有
g(x2) = g(x1) + c(x1,x2) - OPEN表中的节点在任意时刻都是按照代价的大小排序的,每次都选择代价最小的进行扩展
- 是完备搜索,如果有解,定必可以求出最优解
- 代价树的深度优先搜索
- 每次从刚扩展的子节点中,选择代价最小的进行考察
- 是不完备的,可能陷入无穷分支或局部最优
- 宽度优先
- 搜索方法(启发式搜索)
- 启发式搜索一般属性
- 估计函数
f(x) = g(x) + h(x)- 其中g(x)是从初始节点到目标节点已经实际付出的代价
- h(x)是当前节点到目标节点估计的代价,h(x)称为启发函数,体现了问题的启发性信息
- 估计函数
- 局部择优搜索
- 每次一个节点扩展以后,按f(x)最小节点进行扩展,由于每次只在子节点范围内选择,因此称为局部择优
- 全局择优搜索
- 每次从OPEN表的全体节点中,选择一个估计值最小的节点进行扩展
- 有序搜索
- 前面的搜索都是针对树状结构,每个节点只有一个父节点,如果搜索的是有向图,就会有多个父节点,从而导致大量的搜索冗余
- 每次产生一个新节点i时,与所有已经生产的节点进行比较,若节点i是一个已经产生的节点,则表示找到一个通过节点i的新路径,如果节点i的值更小,则更新节点i的父节点指针
- 启发式搜索一般属性
- 数据结构
与或树的搜索方法
- 可解与不可解的确定
- “与”节点只有全部节点可解时,才可解
- “或”节点只要有一个节点可解,就可解
- 搜索方法
- 宽度优先算法
- 与状态空间基本一致
- 主要区别在于,在搜索过程中需要多次调用可解标识过程或不可解标识过程
- 从OPEN表读取一个节点,判断是否是可扩展
- 如果可扩展,对其进行扩展,并存入OPEN表
- 对每个扩展节点分析是否为终止节点
- 如果是,则标识这些节点是都可解,并递归的标识其父节点
- 如果可以标识到初始节点,则问题可解,否则删除标识过程的可解先辈节点
- 对每个扩展节点分析是否为终止节点
- 如果不可扩展,标记为不可解节点
- 递归的标识其父辈节点
- 如果可以标识到初始节点,则问题不可解,否则删除标识过程中的不可解前辈节点
- 如果可扩展,对其进行扩展,并存入OPEN表
- 深度优先搜索
- 每次将刚生产的节点置于OPEN表的首部
- 有序搜索
- 解树的代价
- 设
c(x,y)表示节点x到节点y的代价 - 如果x是终结节点,则定义x的代价h(x) = 0
- 如果x是”或”节点,则x的代价为
h(x) = min{c(x,yi) + h(yi)} - 如果x是”与”节点,则x的代价有两种方法
- 和代价法:
h(x) = ∑(c(x,yi) + h(yi)) - 最大代价法:
h(x) = max{c(x,yi) + h(yi)}
- 和代价法:
- 如果x不可扩展,又不是终止节点,则h(x)为无穷大
- 按照上述方法逐步推导,就可以求出初始节点的代价,也就是解树的代价
- 设
- 希望树
- 希望树是搜索过程中,最有可能称为最优解树的那棵树
- 与或树的启发式搜索过程就是不断的选择,修正希望树的过程
- 解树的代价
- 宽度优先算法
## 第四章 经典逻辑推理
推理类型
- 演绎推理
- 从已知的一般性知识出发,去推出蕴含在其中的个别情况的的结论,核心是三段论
- 不能增加新知识
- 归纳推理
- 由个别到一般的推理方法,从足够多的事例中归纳一般性的结论
- 是增加新知识的过程
- 默认推理
- 又称缺省推理,是知识不完全的情况下的推理
谓词公式化为字句集
- 消去蕴含和等价
- 将否定移动到紧靠谓词的位置
- 确保每个否定只作用于一个谓词
- 对变元标准化
- 不同子句中的变量名通过替换使得互不相同
- 从而避免后续的合并中产生冲突
- 化为前束范式
- 所有量词移动到公式最左边
- 移动时不能改变相对顺序
- 消去存在量词
- 如果存在量词不再全称量词的辖域中,直接用个体变元替换
- 否则使用全称量词的函数替换
- 化为标准形
- 即子句之间变换成合取式(and)
- 其中的析取部分(or)可以使用析取对和合取分配律展开
- 消去全称量词
- 消去合取式
- 更换变量名
- 任意两个子句中不能出现同样的变量名
- 因为所有子句都是在全称量词的辖域内,且任意两个子句之间没有任何关系
Skelem函数特性
- 在谓词公式化子句集的过程中,如果Skelem函数不同,则最后结果也不唯一
- 如果原谓词公式为不可满足式,则转化后的子句集也不可满足
- 如果原谓词公式非永假,则子句集并不一定等价
- 设有谓词公式F,其标准子句集为S,则F为不可满足的充要条件是S为不可满足
归结式的定义及性质
- 若P是原子谓词公式,则称P与非P为互补文字
- 设C1与C2是子句集中任意两句,若C1中文字L1与C2中文字L2互补,那么可以从C1与C2中分别消去L1与L2,并将C1与C2中余下的部分按析取关系构成一个新的子句C12,这样过程称为归结
- C12是C1与C2的归结式,C1和C2是C12的亲本子句
基于归结反演的问题求解
- 将已知前提使用谓词公式表示,并转化为子句集
- 把带求解的问题也用谓词公式表示,然后将其否定式与谓词ANSWER构成一个析取式.
- ANSWER是为了求解问题而专设的谓词,其变元数量和变元名必须与问题公式的变元完全一致
- 把此析取式化为子句集,并且把该子句集并入到子句集S中,得到S’
- 对S’使用归结原理进行归结
- 若在归结树的根节点中仅仅得到归结式ANSWER,则答案就在ANSWER中
1 | 已知: 张和李是同班同学,如果x和y是同班同学,则x的教室也是y的教室,现在张在325上课 |
## 第五章 专家系统
专家系统结构
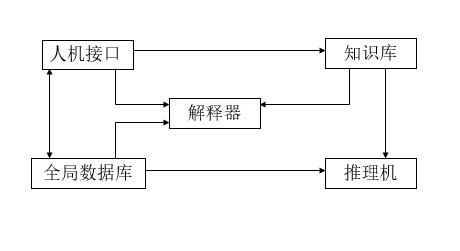
- 知识库(Knowledge Base)
- 以某种存储结构存储的专家知识
- 全局数据库(Global Database)
- 也称黑板
- 存储求解问题的初始数据和推理得到的中间数据,以及最后的推理结论
- 推理机(Reasoning Machine)
- 根据全局数据库的当前内容,从知识库中选择匹配成功的规则,并通过执行可用规则来修改数据库中的内容
- 解释机构(Expositor)
- 用于向用户解释专家系统的行为
- 包括解释”系统怎样得到这一结论”,”系统微信么要提出这样的问题来询问用户”等
- 用户接口(Interface)
- 系统与用户进行对话的界面
- 用户通过接口输入必要的数据,提出问题和输出推理结果,以及向用户做出解释等
- 知识获取
- 把知识工程师提供的知识转化为知识的内部标识模式并存入知识库中
- 在存储过程中,对知识的一致性,完整性检查
## 第六章 不确定推理
知识的不确定性
- 证据的不确定性
- 证据的歧义性: 证据可以由多种理解
- 证据的不完全性
- 证据尚未收集完全
- 证据的特征值不完全
- 证据的不精确性
- 证据的模糊性
- 证据的可信性
- 证据的随机性
- 规则的不确定性
- 规则前件的不确定性(信息的可信度)
- 规则前件的证据组合的不确定性(组合方式)
- 规则本身的不确定性(规则强度)
- 规则结论的不确定性(推论最后的可信度)
- 推理的不确定性
- 证据组合的不确定测度计算模式
- 合取计算方式
- CF(e1∧e2) = min(CF(e1),CF(e2))
- 析取计算方式
- CF(e1∨e2) = max(CF(e1),CF(e2))
- 否定计算方式
CF(﹁e) = - CF(e)
- 合取计算方式
- 并行规则的不确定测度计算模式
- 即如果有多个规则可以获得同一结论,求结论的h的不确定度
- CF(h,e1e2) = CF(h,e1) + CF(h,e2) - CF(h,e1)CF(he2) (同正)
- CF(h,e1e2) = (CF(h,e1) + CF(h,e2)) / (1 - min( |CF(h,e1)| , |CF(h,e2| )) (异号)
- CF(h,e1e2) = CF(h,e1) + CF(h,e2) + CF(h,e1)CF(he2) (同负)
- 顺序(串行)规则的不确定测度计算模式
- 如果有if e1 then e2 和 if e2 then h 求 if e then h 的不确定度
- CF(h,e1) = CF(h,e2) X max(0,CF(e2,e1))
- 一个系统只要给定上述三个情况的计算方法,即可获得各种证据组合的不确定度
- 证据组合的不确定测度计算模式
信任度
- 信任度MB(h,e)表示证据e出现时,对h成立的信任程度的增加量
- 不信任度MD(h,e)表示证据e出现时,对h成立的不信任程度的增加量
- 两者的取值范围都是[0,1]
- 其中一个大于零,则另一个必定为零
可信度
- CF(h,e) = MB(h,e) - MD(h,e)
- 取值范围是[-1,1]
- 大于零表示证据e可以增加h的可信度
- 小于零表示证据e可以减少h的可信度
- 等于零表示证据e与h无关
最后更新: 2026年07月13日 14:43
版权声明:本文为原创文章,转载请注明出处
原始链接: https://lizec.top/2017/12/31/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD%E6%A6%82%E8%AE%BA/